
Ever launched an A/B test, watched the numbers roll in, and felt that familiar pang of uncertainty? You’re not alone. Many marketers and product managers diligently run A/B tests, but often struggle with one crucial question: Is this result real, or just a fluke? This is where A/B testing statistical significance explained becomes your North Star. It’s the difference between making confident, data-driven decisions that propel your business forward and blindly chasing phantom gains.
Think of it like this: You’re flipping a coin to decide between two marketing headlines. If it lands on heads once, does that mean heads is always better? Of course not! You need to flip it many, many times to be sure. A/B testing is similar, but with far more at stake than a coin toss. Without understanding statistical significance, you might celebrate a “win” that’s purely random, or worse, dismiss a genuinely impactful change because you couldn’t discern its true effect. This article will demystify the concept, providing you with the powerful secrets to ensure your A/B tests lead to valid, actionable insights, every single time. Let’s dive in and transform your testing approach.
Understanding the Core: What is A/B Testing Statistical Significance Explained?
At its heart, A/B testing statistical significance explained refers to the probability that the difference observed between two versions (A and B) of a webpage, app feature, or marketing campaign is not due to random chance, but rather a true, underlying difference. In simpler terms, it tells you how confident you can be that if you were to run the same test again, you’d get similar results. It’s about separating the signal from the noise in your data.
Imagine you’re testing two different call-to-action buttons: one red, one blue. After a week, the red button has a 5% conversion rate, and the blue button has a 6% conversion rate. Is that 1% difference meaningful? Or could it just be random variation? Statistical significance helps answer this. It quantifies the likelihood that the observed difference is real and not just a fluke of the specific sample of users who participated in your test. A higher statistical significance means a lower probability that your results are due to random chance.
This concept is crucial because without it, you risk making decisions based on misleading data. Implementing a change that appears to be a winner but is actually a false positive can lead to wasted resources, missed opportunities, and even negative impacts on your key metrics. Conversely, overlooking a genuine improvement because you couldn’t confidently interpret your A/B test results is equally detrimental. Understanding this core principle is the bedrock of effective, data-driven optimization.
The Math Behind the Magic: How to Calculate A/B Test Statistical Significance
Now, let’s get to the nitty-gritty: how do we calculate A/B test statistical significance? While many online calculators exist to do the heavy lifting, understanding the underlying principles empowers you to interpret results more effectively. The core idea revolves around hypothesis testing, where we propose a null hypothesis (no difference between variations) and an alternative hypothesis (there is a difference).
The most common method for calculating statistical significance in A/B testing involves using a Z-test or a Chi-squared test, depending on the type of data. For conversion rates, which are binary outcomes (converted or not converted), a Z-test is frequently employed. The formula for the Z-score in comparing two proportions is:
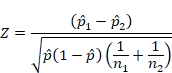
Where: – ![]() and
and ![]() are the conversion rates of variation 1 and variation 2, respectively. –
are the conversion rates of variation 1 and variation 2, respectively. – ![]() and
and ![]() are the number of visitors for variation 1 and variation 2. –
are the number of visitors for variation 1 and variation 2. – ![]() is the pooled conversion rate, calculated as
is the pooled conversion rate, calculated as ![]() , where
, where ![]() and
and ![]() are the number of conversions for each variation.
are the number of conversions for each variation.
Once you have the Z-score, you can look up its corresponding p-value. The p-value is the probability of observing a difference as extreme as, or more extreme than, the one you measured, assuming the null hypothesis is true (i.e., there’s no real difference). A commonly accepted threshold for statistical significance is a p-value of 0.05 (or 5%). This means there’s less than a 5% chance that the observed difference is due to random chance. If your p-value is below this threshold, you can reject the null hypothesis and conclude that your results are statistically significant.
It’s not just about the formula, though. (Though the formula is pretty cool, isn’t it?) Factors like sample size and the magnitude of the observed difference play a huge role. A small difference might require a much larger sample size to achieve statistical significance. Conversely, a very large difference might be significant even with a smaller sample. Tools and calculators simplify this, but knowing the ‘why’ behind the ‘what’ is invaluable for any serious optimizer. So, when you’re looking to calculate A/B test statistical significance, remember it’s a blend of careful data collection and understanding these core mathematical principles.

Beyond the Numbers: Interpreting A/B Test Results Accurately
Calculating statistical significance is one thing; truly interpreting A/B test results is another. It’s not just about hitting that magical p-value of 0.05. A statistically significant result tells you that a difference likely exists, but it doesn’t tell you why it exists, nor does it guarantee business impact. This is where qualitative analysis, user behavior insights, and a healthy dose of critical thinking come into play.
First, always consider the magnitude of the difference. A 0.1% increase in conversion rate might be statistically significant if your sample size is enormous, but is it practically significant for your business? Sometimes, a smaller, non-statistically significant uplift might be worth exploring further if it aligns with other qualitative data or strategic goals. Conversely, a large, statistically significant difference is a clear indicator of a strong performer.
Second, look beyond the primary metric. Did the winning variation negatively impact other important metrics, like average order value or bounce rate? A holistic view of your data is essential. For instance, a new checkout flow might increase conversions but also lead to more customer support inquiries. That’s not a win, is it?
Third, understand the context. Who were the users in your test? What was their journey like? Were there any external factors that could have influenced the results (e.g., a holiday sale, a news event)? These contextual elements are vital for accurately interpreting A/B test results and preventing misinterpretations. Don’t just look at the numbers in isolation; they tell only part of the story. The real insights come from combining quantitative data with qualitative understanding. This nuanced approach ensures that your data-driven decisions are not just statistically sound, but also strategically smart.
The Unseen Advantage: Importance of Statistical Significance A/B Testing
The importance of statistical significance A/B testing extends far beyond simply validating a test result. It forms the bedrock of a truly data-driven culture, enabling organizations to make confident, informed decisions that drive sustainable growth. Without it, A/B testing becomes a guessing game, prone to false positives and wasted effort.
One of the primary advantages is risk mitigation. By ensuring that observed differences are statistically significant, you reduce the risk of implementing changes that have no real impact or, worse, a negative one. This is particularly crucial in high-stakes environments where even small errors can have significant financial repercussions. It’s like building a bridge; you wouldn’t want to cross it if you weren’t statistically significant that it would hold, would you?
Furthermore, statistical significance fosters trust and credibility within your team and with stakeholders. When you can confidently present results and explain that the improvements are not merely coincidental, it builds confidence in your optimization efforts. This, in turn, encourages further investment in testing and a greater willingness to embrace experimentation as a core business practice. It transforms A/B testing from a tactical exercise into a strategic imperative.
Finally, understanding the importance of statistical significance A/B testing allows for more efficient resource allocation. Instead of chasing every minor uplift, you can focus your efforts on changes that have a demonstrable, reliable impact. This means less time spent on ineffective iterations and more time dedicated to scaling proven winners. It’s about working smarter, not just harder, and ensuring every experiment contributes meaningfully to your overarching business objectives. This unseen advantage is what separates casual testers from true optimization masters.
Common Pitfalls and How to Avoid Them
Even with a solid grasp of A/B testing statistical significance explained, pitfalls abound. Avoiding these common mistakes is just as crucial as understanding the concepts themselves. Here are some traps to watch out for:
1. Peeking at Results Too Early: This is perhaps the most common and damaging mistake. Stopping a test as soon as you see a statistically significant result, especially if it’s positive, can lead to false positives. Statistical significance is calculated based on a predetermined sample size or test duration. Peeking early inflates the chance of seeing a significant result purely by chance. Always pre-determine your sample size or test duration and stick to it. Patience, young padawan, patience!
2. Not Running Tests Long Enough: Conversely, ending a test too soon, even if you haven’t reached statistical significance, can lead to inconclusive results. You need enough data to smooth out random fluctuations. Factors like weekly cycles, seasonality, and traffic patterns should influence your test duration. A test that runs for less than a full business cycle (e.g., a week) might miss important behavioral patterns.
3. Ignoring Practical Significance: As discussed, statistical significance doesn’t always equate to practical significance. A tiny, statistically significant uplift might not be worth the development effort or the potential disruption to user experience. Always weigh the statistical findings against the real-world impact and business goals.
4. Testing Too Many Variables at Once: Trying to change too many elements in a single A/B test makes it impossible to isolate which specific change caused the observed effect. This is why A/B testing is often called
“split testing” – you’re splitting your audience to test one variable. If you want to test multiple variables, consider multivariate testing, but be aware it requires significantly more traffic and a more complex setup.
5. Not Accounting for Novelty Effect: Sometimes, a new design or feature performs well simply because it’s new and grabs attention. This “novelty effect” can fade over time. For significant changes, consider running tests for a longer duration or re-testing after a period to see if the uplift persists.
6. Invalidating Tests with External Factors: Be mindful of external events that could skew your test results. A sudden marketing campaign, a major news event, or even a technical glitch can invalidate your test. Monitor your analytics closely for any anomalies during the test period.
By being aware of these common pitfalls and actively working to avoid them, you can significantly improve the quality and reliability of your A/B tests, ensuring that your efforts in A/B testing statistical significance explained truly lead to valid, data-driven decisions.

Real-World Applications: Case Studies in Data-Driven Success
Understanding A/B testing statistical significance explained isn’t just theoretical; its power truly shines in real-world applications. Companies across various industries leverage this methodology to optimize everything from website conversion rates to email open rates, demonstrating the tangible impact of data-driven decisions. Let’s look at a few illustrative examples, highlighting how businesses have used A/B testing to achieve significant gains.
Case Study 1: E-commerce Conversion Optimization
A prominent online retailer was struggling with a high cart abandonment rate. They hypothesized that simplifying the checkout process could improve conversions. They ran an A/B test comparing their existing multi-step checkout (Variation A) with a new, streamlined one-page checkout (Variation B). After collecting sufficient data and ensuring A/B testing statistical significance explained was achieved, they found that Variation B led to a 15% increase in completed purchases with a p-value of 0.01. This statistically significant result gave them the confidence to fully implement the new checkout flow, leading to millions in additional revenue annually.
| Feature | Original Checkout (A) | Streamlined Checkout (B) |
| Number of Steps | 5 | 1 |
| Conversion Rate | 2.5% | 2.875% |
| Statistical Significance | N/A | p < 0.05 |
| Impact | Baseline | +15% Conversions |
Case Study 2: SaaS Onboarding Flow Improvement
A Software-as-a-Service (SaaS) company wanted to improve their user activation rate, which is the percentage of new sign-ups who complete a key onboarding action. They tested two different onboarding flows: the original flow with a generic welcome email (Variation A) and a new flow that included a personalized in-app tutorial and a targeted email sequence (Variation B). The test ran for four weeks, and the results showed that Variation B increased user activation by 22% with a p-value of 0.03. This demonstrated the importance of statistical significance A/B testing in validating personalized user experiences.
| Onboarding Element | Original Flow (A) | Personalized Flow (B) |
| Welcome Email | Generic | Targeted |
| In-App Tutorial | None | Guided |
| User Activation Rate | 18% | 21.96% |
| Statistical Significance | N/A | p < 0.05 |
| Impact | Baseline | +22% Activation |
Case Study 3: Media Company Engagement
A large online media publisher aimed to increase reader engagement, specifically time spent on page. They hypothesized that larger, more prominent article images would capture more attention. They conducted an A/B test where Variation A had standard-sized images and Variation B featured larger, hero-style images. After analyzing the data, they found that Variation B resulted in a 7% increase in average time on page, with a p-value of 0.04. This seemingly small but statistically significant improvement, when scaled across millions of daily visitors, translated into substantial gains in advertising impressions and overall engagement, underscoring the power of even subtle changes when backed by robust data.
| Image Size | Standard (A) | Hero-Style (B) |
| Average Time on Page | 2:30 min | 2:40.5 min |
| Statistical Significance | N/A | p < 0.05 |
| Impact | Baseline | +7% Time on Page |
These examples illustrate that whether you’re looking to calculate A/B test statistical significance for conversions, engagement, or any other key metric, the principles remain the same. The ability to confidently attribute changes in user behavior to specific variations is what makes A/B testing an indispensable tool for continuous improvement and innovation.
Conclusion: Your Path to Confident, Conversion-Boosting Decisions
We’ve journeyed through the intricacies of A/B testing statistical significance explained, from its fundamental definition to the practicalities of calculation, interpretation, and avoiding common pitfalls. What should be abundantly clear by now is that statistical significance isn’t just a buzzword; it’s the scientific backbone of effective experimentation. It’s what transforms raw data into reliable insights, enabling you to make decisions with confidence, not just hope.
Embracing statistical significance means moving beyond gut feelings and anecdotal evidence. It means understanding that every A/B test is an opportunity to learn, to refine, and to optimize. By diligently applying these principles, you’ll not only validate your hypotheses but also uncover genuine opportunities for growth that might otherwise remain hidden. Remember, the goal isn’t just to run tests, but to run meaningful tests that yield actionable results.
So, what’s your next step? Start by reviewing your past A/B tests. Were they truly statistically significant? Could you have calculated A/B test statistical significance more accurately? Begin to integrate these principles into your future testing strategy, ensuring every experiment is designed with statistical rigor in mind. The path to confident, conversion-boosting decisions is paved with valid data, and A/B testing statistical significance explained is your ultimate guide. Go forth and optimize!
Frequently Asked Questions (FAQs)
What is the primary purpose of statistical significance in A/B testing?
The primary purpose is to determine whether the observed difference between two variations in an A/B test is likely due to a real effect or simply random chance. It helps ensure that decisions are based on reliable data.
What is a p-value, and how does it relate to statistical significance?
The p-value is the probability of observing a result as extreme as, or more extreme than, the one measured, assuming there is no real difference between the variations (the null hypothesis is true). A p-value typically below 0.05 indicates statistical significance, meaning the observed difference is unlikely due to chance.
Why is sample size important for statistical significance?
Sample size directly impacts the reliability of your results. A larger sample size reduces the margin of error and increases the power of your test to detect a true difference, making it easier to achieve statistical significance if a real effect exists.
Can a test be practically significant but not statistically significant?
Yes. A small observed difference might be practically important for your business but may not reach statistical significance if the sample size is too small. Conversely, a statistically significant result might have a negligible practical impact.
How long should I run an A/B test to achieve statistical significance?
There’s no fixed duration. The test duration depends on your traffic volume, the expected uplift, and the desired level of statistical significance. It’s crucial to run the test long enough to gather sufficient data and account for weekly cycles and other behavioral patterns.
6. What are some common mistakes to avoid when aiming for statistical significance?
Common mistakes include peeking at results too early, not running tests long enough, ignoring practical significance, testing too many variables at once, and not accounting for the novelty effect. Always plan your tests rigorously and adhere to your predetermined parameters.
References
- VWO Blog: https://vwo.com/blog/15-free-ab-split-testing-resources/
- SurveyMonkey A/B Testing Calculator: https://www.surveymonkey.com/mp/ab-testing-significance-calculator/
- Data36.com: https://data36.com/statistical-significance-in-ab-testing/
- Neil Patel A/B Testing Calculator: https://neilpatel.com/ab-testing-calculator/
- NN/g (Nielsen Norman Group ): https://www.nngroup.com/videos/ab-testing-101/
- Optimizely: https://www.optimizely.com/optimization-glossary/ab-testing/








